1. Introduction
Long-context capability is pivotal for modern machine learning, particularly in natural language processing and time series analysis. However, maintaining context over extended sequences remains a bottleneck. As shown in the figure below, processing a long document with the Qwen3-4B model leads to an explosion in KV cache usage.
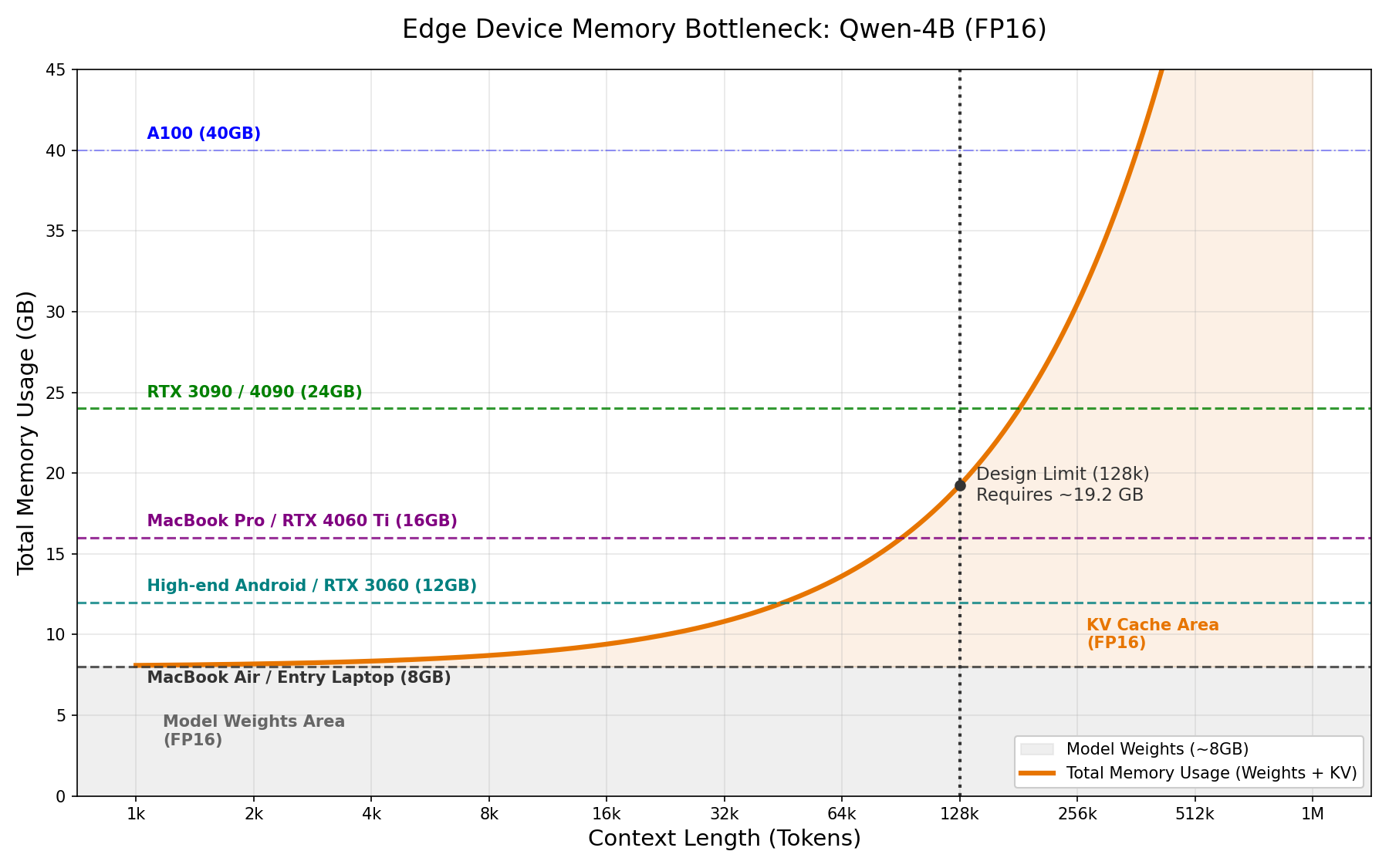
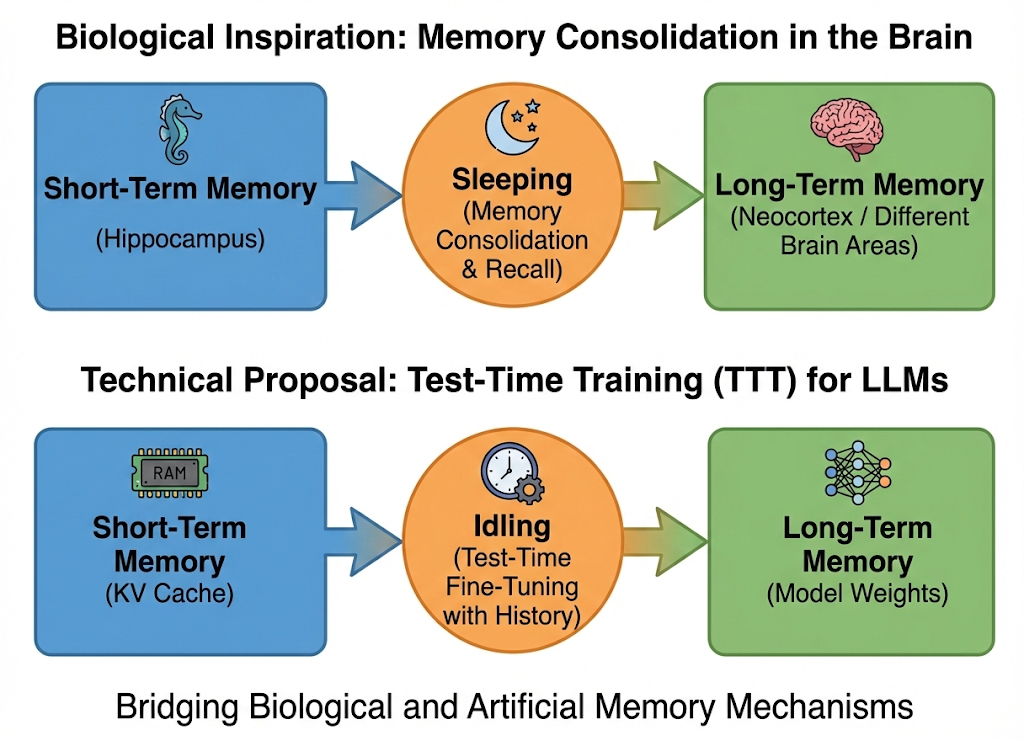
This contrasts sharply with biological intelligence. Unlike humans, whose hippocampus consolidates short-term working memory into long-term storage (often during sleep), LLMs rely solely on a growing raw buffer—the KV cache. Setting aside RAG (which acts more like an external notebook than an internal brain), I wonder if we can engineer a similar "memory consolidation" mechanism for LLMs. Specifically, can we leverage fine-tuning to compress history directly into model weights? By doing so, we could drastically reduce the KV cache footprint and improve inference speed. While training is computationally expensive, LLMs are not always active; we can potentially utilize the intervals between user queries—such as waiting for tool feedback or human response—to perform this optimization. This initial post explores the feasibility of this idea and the challenges that lie ahead.
2. Related Work: The Landscape of Long Context
To tackle the "memory wall" in LLMs, researchers have explored three main directions. Here, I discuss why existing solutions might not be the final answer and how TTT fits into the picture.
2.1 Architectural Alternatives & The "Capacity Limit"
One direction is to design new memory forms, often inspired by RNNs. Linear Attention mechanisms (like RWKV or Mamba) compress history into a fixed-size state, allowing for O(N) inference. Google's recent Titans also introduces a "Neural Memory" module that explicitly manages memorization and forgetting.
However, these methods face a theoretical ceiling. As pointed out in this paper, linear attention stores information in a matrix and retrieves it via dot products. Crucially, effective retrieval requires the keys to be orthogonal. This implies that once the sequence length exceeds the dimension capacity (overcapacity regime), the model suffers from unavoidable retrieval errors due to interference. This explains why they often struggle with long context.
2.2 KV Cache Optimization: Pruning & Sparsity
For standard Transformers, another line of work focuses on managing the existing KV cache:
- Cache Eviction (Reducing Space): Methods like SnapKV, H2O, and StreamingLLM identify and evict "unimportant" tokens to keep the cache size constant. While this accelerates inference and saves memory, it is inherently lossy—if the answer lies in an evicted token, the model hallucinates.
- Sparse Attention (Accelerating Compute): Other methods select only the top-K relevant tokens for calculation (e.g., Less Is More). While this speeds up the attention operation, it doesn't necessarily reduce the memory footprint if the full cache still needs to be stored for selection.
2.3 Test-Time Training (TTT): The "Third Path"
This brings us to Test-Time Training (TTT). Analogous to the human brain, TTT allows the model to "learn" (update weights) from the context on-the-fly. Recently, TTT-E2E achieve to outperform linear attention trough test-time training. Specifically, they modify model architecture, optimize the training loss and train a model from scratch.
However, TTT-E2E requires pre-training a novel architecture from scratch. This is computationally expensive and discards the massive knowledge embedded in existing open-source models.
My Hypothesis: Can we leverage the TTT capability inherent in existing frozen LLMs? Instead of designing a new TTT model, can we directly use TTT for existing models, thereby save space and accelerate inference?
3. Can the model learn?
One of the main problems of TTT is that when training the model with the long context, we want the model to learn the token sequence, while models possibly are learning the distribution instead. That is, we want the model to memorize specific sequences rather than generalize from them. Therefore, it is necessary to validate TTT.
To test this, I set up a simple experiment using Qwen3-4B. I use my own version of Needle-In-A-Haystack(NIAH), whose detailed design is shown below.
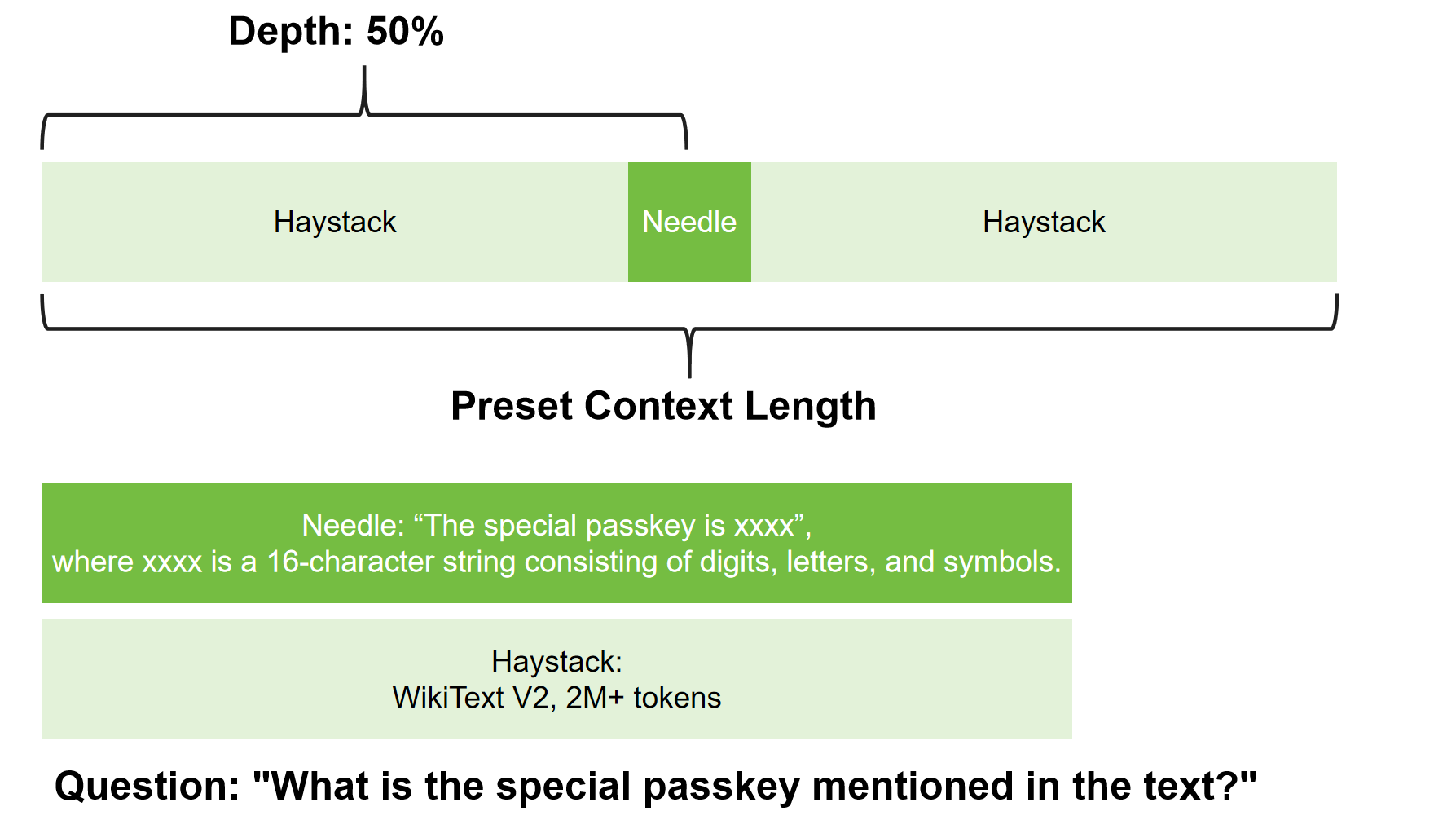
In this experiment, I train the model with the needle and haystack sequences. And then, the model is provided with merely the question, asking to recall the needle sequence from the haystack. I choose different training configurations to observe the model's learning behavior, including LoRA and full fine-tuning.
TODO: QKVO VS MLP, Longer Context4. What have the model learnt?
Recently I wrote some scripts to visualize the hidden states...
5. Future Work
There are several promising directions to explore: